
En la conferencia Ray Summit de este año, nos complace presentar la stack de infraestructura que diseñamos con IBM Research, que incluye Ray y CodeFlare para las cargas de trabajo distribuidas de inteligencia artificial generativa. Se presentan las tecnologías a las comunidades open source como Open Data Hub y se consolidan para convertirse en parte de Red Hat OpenShift AI, que también es compatible con IBM watsonx.ai y los modelos base de IBM que utiliza Red Hat Ansible Automation Platform. Red Hat OpenShift AI reúne un conjunto potente de herramientas y tecnologías diseñadas para que el proceso de perfeccionamiento y distribución de los modelos base sea sencillo, flexible y eficiente. Con ellas, puede ajustar, entrenar e implementar modelos de manera uniforme, ya sea en sus instalaciones o en la nube. Nuestro trabajo más reciente ofrece varias opciones para perfeccionar y distribuir modelos base, lo que brinda a los especialistas en análisis de datos y MLOps funciones como el acceso inmediato a los recursos del clúster o la capacidad de programar las cargas de trabajo para que se procesen por lotes.
En esta publicación, aprenderá a usar Red Hat OpenShift IA para perfeccionar sin inconvenientes un modelo GPT-2 de HuggingFace con 137 millones de parámetros en un conjunto de datos WikiText y, luego, podrá implementarlo. Usaremos la stack de Distributed Workloads con KubeRay para realizar el paralelismo durante el perfeccionamiento, y la stack de KServe/Caikit/TGIS para implementar y supervisar nuestro modelo base GPT- 2 ya perfeccionado.
La stack de Distributed Workloads consta de dos elementos principales:
- KubeRay: es un operador de Kubernetes para la implementación y la gestión de clústeres de Ray remotos que ejecutan cargas de trabajo informáticas distribuidas.
- CodeFlare: se trata de un operador de Kubernetes que implementa y gestiona el ciclo de vida de tres elementos:
- CodeFlare-SDK: es una herramienta para definir y controlar la infraestructura y los trabajos informáticos distribuidos remotos. El operador CodeFlare implementa un notebook con CodeFlare-SDK.
- Multi-Cluster Application Dispatcher (MCAD): es un controlador de Kubernetes que se utiliza para gestionar trabajos por lotes en un entorno de uno o varios clústeres.
- InstaScale: sirve para ajustar los recursos agrupados en todas variedades de OpenShift según se solicite con la configuración de MachineSets (autogestionados o gestionados: Red Hat OpenShift en AWS/Open Data Hub)
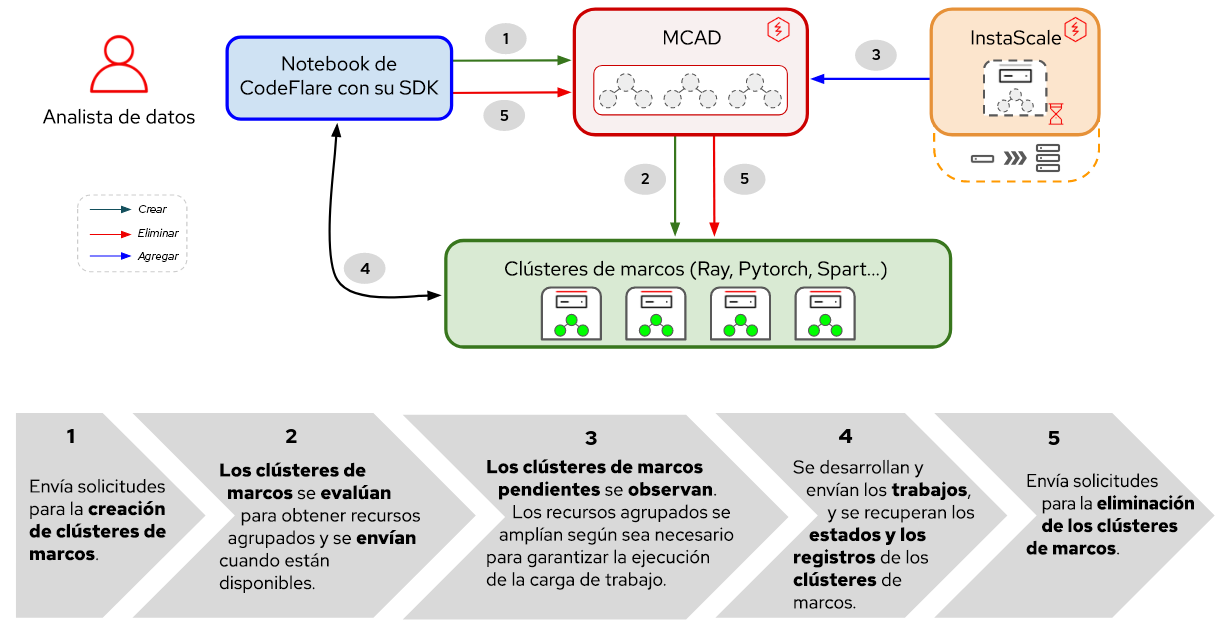
Figura 1. Interacciones entre los elementos y el flujo de trabajo del usuario en Distributed Workloads.
Como se muestra en la Figura 1, en Red Hat OpenShift AI el ajuste de su modelo base comienza con CodeFlare, un marco dinámico que optimiza y simplifica el diseño, el entrenamiento y el perfeccionamiento de los modelos. Además, aprovechará la potencia del marco informático distribuido Ray, con el cual se usa KubeRay para distribuir de manera eficiente las iniciativas de ajuste, lo cual reduce de manera considerable el tiempo requerido para lograr un rendimiento óptimo del modelo. Una vez definida la carga de trabajo de perfeccionamiento, MCAD pone en la cola la carga de trabajo de Ray hasta que se cumplan los requisitos de recursos y crea el clúster de Ray cuando está garantizado que se pueden programar todos los pods.
Por otro lado, la stack de KServe/Caikit/TGIS incluye:
- KServe: es una definición de recursos personalizados de Kubernetes que se utiliza para distribuir modelos de producción y se ocupa de su ciclo de vida de implementación.
- Text Generation Inference Server (TGIS): se trata de un servidor o backend de distribución que carga los modelos y proporciona el motor de inferencia.
- Caikit: es un kit de herramientas o tiempo de ejecución de inteligencia artificial que maneja el ciclo de vida del proceso de TGIS y ofrece módulos y extremos para las inferencias que son compatibles con diferentes tipos de modelos.
- OpenShift Serverless (operador necesario): se basa en el proyecto open source Knative, el cual permite que los desarrolladores diseñen e implementen aplicaciones empresariales sin servidor y basadas en eventos.
- OpenShift Service Mesh (operador necesario): se basa en el proyecto open source Istio, el cual proporciona una plataforma para obtener información sobre el comportamiento de los microservicios en la red en una malla de servicios y ofrecerles control operativo.

Figura 2. Interacciones entre los elementos y el flujo de trabajo del usuario en la stack de KServe/Caikit/TGIS.
Una vez que se perfecciona el modelo, se implementa con el tiempo de ejecución y el backend de distribución de Caikit/TGIS, lo cual simplifica y agiliza el ajuste y el mantenimiento con KServe para ofrecer una infraestructura de distribución confiable y avanzada. En segundo plano, Red Hat OpenShift Serverless (Knative) prepara la implementación sin servidor del modelo, y Red Hat OpenShift Service Mesh (Istio) gestiona todos los flujos de tráfico y redes (consulte la Figura 2).
Configuración del entorno
En esta demostración, se asume que tiene un clúster de OpenShift con el operador Red Hat OpenShift Data Science instalado o agregado como complemento. También puede ejecutarse con Open Data Hub como plataforma principal.
Para perfeccionar su modelo, deberá instalar el operador de la comunidad CodeFlare que se encuentra disponible en OperatorHub. Con él, se instalan MCAD, InstaScale, el operador KubeRay y la imagen del notebook CodeFlare con paquetes como CodeFlare-SDK, PyTorch y TorchX incluidos. Si usa unidades de procesamiento de gráficos (GPU), también deberán instalarse los operadores NVIDIA GPU y Node Feature Discovery.
Para distribuir el modelo, puede simplemente ejecutar este script para instalar todos los operadores necesarios y la stack completa de KServe/Caikit/TGIS. Establezca TARGET_OPERATOR en rhods.
Si bien las instrucciones de instalación para las stacks de Distributed Workloads y KServe/Caikit/TGIS son bastante manuales en este punto, ambas estarán disponibles en Red Hat OpenShift Data Science y serán compatibles con la plataforma pronto.
Perfeccionamiento de un modelo de lenguaje de gran tamaño (LLM)
Primero, lance el notebook de CodeFlare desde el panel de Red Hat OpenShift AI (consulte la Figura 3) y cree una copia del repositorio de demostración que incluye el notebook y otros archivos necesarios.

Figura 3. Imagen del notebook de CodeFlare que se muestra en el panel de OpenShift Data Science.
Al principio, debe definir los parámetros para el tipo de clúster que desea (ClusterConfiguration), como el nombre, el espacio de nombres en el que se implementará, los recursos de CPU, GPU y memoria requeridos, los tipos de máquinas y su decisión sobre el uso de la función de ajuste automático de InstaScale. Si trabaja en un entorno local, puede ignorar machine_types y establecer instascale=False. Después, se genera el objeto del clúster y se envía a MCAD para poner en marcha el clúster de Ray.
Cuando el clúster de Ray esté listo y pueda ver su información desde el comando cluster.details() en el notebook, deberá definir la tarea de perfeccionamiento al proporcionar un nombre, el script que se ejecutará, los argumentos (si los hay) y una lista de las bibliotecas necesarias, y luego la enviará al clúster de Ray que acaba de iniciar. La lista de argumentos especifica el modelo GPT-2 que se usará y el conjunto de datos WIkiText con el que se perfeccionará. Lo mejor de CodeFlare-SDK es la facilidad con la que puede realizar un seguimiento del estado, los registros y otra información, ya sea a través de la CLI o de un panel de Ray.
Una vez que se completa el proceso de perfeccionamiento del modelo, puede ver que el resultado de job.status()cambia a SUCCEEDED y los registros en el panel de Ray muestran que finalizó la tarea (consulte la Figura 4). Con un nodo de trabajo de Ray en ejecución en la GPU T4 NVIDIA, con 2 CPU y 8 GB de memoria, el perfeccionamiento del modelo GPT2 tomó aproximadamente 45 minutos.

Figura 4. Los registros del panel de Ray muestran que finalizó el proceso de perfeccionamiento del modelo.
Luego, deberá crear un nuevo directorio en el notebook, guardar el modelo allí y descargarlo en su entorno local para convertirlo y cargarlo a un bucket de MinIO posteriormente. Tenga en cuenta que en esta demostración se usa un bucket de MinIO; sin embargo, puede elegir otro tipo de bucket de S3, PVC o el almacenamiento que prefiera.
Distribución del modelo LLM
Una vez que perfeccionó su modelo base, es hora de ponerlo en marcha. Desde el mismo notebook donde lo hizo, debe crear un nuevo espacio de nombres en el cual puede:
- Implementar el tiempo de ejecución de distribución de Caikit y TGIS
- Implementar la conexión de datos S3
- Implementar el servicio de inferencia que apunta a su modelo ubicado en un bucket de MinIO
El tiempo de ejecución de distribución es una definición de recurso personalizada que está diseñada para crear un entorno para la implementación y la gestión de modelos en producción. Genera las plantillas para pods que pueden cargar y descargar modelos de varios formatos de forma dinámica y según se solicite y habilitar el acceso a un extremo de distribución de modo que reciba solicitudes de inferencia. Debe implementar el tiempo de ejecución de distribución que ampliará los pods correspondientes una vez que se detecte un servicio de inferencia. Para la inferencia se usará el puerto 8085.
Un servicio de inferencia es un servidor que recibe datos y los pasa al modelo, el cual se ejecuta y devuelve el resultado de la inferencia. En el servicio que implementa, debe especificar el tiempo de ejecución anterior, habilitar la ruta de acceso para que se realice la inferencia de gRPC y dirigir el servidor al bucket de MinIO donde se encuentra el modelo que perfeccionó.
Después de comprobar que el servicio de inferencia está listo, realice una llamada de inferencia para solicitar al modelo que complete una oración cualquiera.
Ya perfeccionó un modelo de lenguaje de gran tamaño GPT-2 con la stack de Distributed Workloads y lo distribuyó con la stack de KServe/Caikit/TGIS en OpenShift AI.
Siguientes pasos
Nos gustaría agradecer a las comunidades de Open Data Hub y Ray por su apoyo. Esto es solo un pequeño ejemplo de los posibles casos prácticos de inteligencia artificial/machine learning (aprendizaje automático) con OpenShift AI. Para obtener más información sobre las funciones de la stack de CodeFlare, consulte el video de demostración que desarrollamos, en el que se abordan en más detalle las secciones sobre CodeFlare SDK, KubeRay y MCAD que se explican en esta demostración.
Muy pronto, integraremos los operadores CodeFlare y KubeRay en OpenShift AI y desarrollaremos la interfaz de usuario para la stack de KServe/Caikit/TGIS que se lanzó recientemente en esta plataforma como una función de disponibilidad limitada. No se lo pierda.
Sobre el autor

Selbi Nuryyeva is a software engineer at Red Hat in the OpenShift AI team focusing on the Open Data Hub and Red Hat OpenShift Data Science products. In her current role, she is responsible for enabling and integrating the model serving capabilities. She previously worked on the Distributed Workloads with CodeFlare, MCAD and InstaScale and integration of the partner AI/ML services ecosystem. Selbi is originally from Turkmenistan and prior to Red Hat she graduated with a Computational Chemistry PhD degree from UCLA, where she simulated chemistry in solar panels.
Navegar por canal

Automatización
Conozca lo último en la plataforma de automatización que abarca tecnología, equipos y entornos

Inteligencia artificial
Descubra las actualizaciones en las plataformas que permiten a los clientes ejecutar cargas de trabajo de inteligecia artificial en cualquier lugar

Nube híbrida abierta
Vea como construimos un futuro flexible con la nube híbrida

Seguridad
Vea las últimas novedades sobre cómo reducimos los riesgos en entornos y tecnologías

Edge computing
Conozca las actualizaciones en las plataformas que simplifican las operaciones en el edge

Infraestructura
Vea las últimas novedades sobre la plataforma Linux empresarial líder en el mundo

Aplicaciones
Conozca nuestras soluciones para abordar los desafíos más complejos de las aplicaciones

Programas originales
Vea historias divertidas de creadores y líderes en tecnología empresarial
Productos
- Red Hat Enterprise Linux
- Red Hat OpenShift
- Red Hat Ansible Automation Platform
- Servicios de nube
- Ver todos los productos
Herramientas
- Training y Certificación
- Mi cuenta
- Recursos para desarrolladores
- Soporte al cliente
- Calculador de valor Red Hat
- Red Hat Ecosystem Catalog
- Busque un partner
Realice pruebas, compras y ventas
Comunicarse
- Comuníquese con la oficina de ventas
- Comuníquese con el servicio al cliente
- Comuníquese con Red Hat Training
- Redes sociales
Acerca de Red Hat
Somos el proveedor líder a nivel mundial de soluciones empresariales de código abierto, incluyendo Linux, cloud, contenedores y Kubernetes. Ofrecemos soluciones reforzadas, las cuales permiten que las empresas trabajen en distintas plataformas y entornos con facilidad, desde el centro de datos principal hasta el extremo de la red.
Seleccionar idioma
Red Hat legal and privacy links
- Acerca de Red Hat
- Oportunidades de empleo
- Eventos
- Sedes
- Póngase en contacto con Red Hat
- Blog de Red Hat
- Diversidad, igualdad e inclusión
- Cool Stuff Store
- Red Hat Summit