
Red Hat OpenShift Data Science: servicios de nube para la IA y el ML
Adopción más rápida de las aplicaciones inteligentes
La inteligencia artificial (IA), el aprendizaje automático (ML) y el aprendizaje profundo (DL) influyen considerablemente en las iniciativas de modernización de las aplicaciones en una infinidad de sectores y negocios. Varias empresas necesitan obtener valor estratégico e información nueva a partir de sus datos, lo cual fomenta el aumento del uso de las aplicaciones inteligentes desarrolladas en la nube y las metodologías de DevOps. Este nuevo mundo tecnológico puede ser complejo e influir en todos, desde los equipos de desarrollo hasta los de análisis de datos y de operaciones. Los enfoques tradicionales presentan algunos desafíos:
- Los comienzos pueden ser desalentadores, ya que se deben mantener actualizados y uniformes las herramientas y los servicios de aplicaciones, a pesar de su rápida evolución. Además, es necesario implementar recursos de hardware, como las unidades gráficas de procesamiento (GPU), y ajustar las aplicaciones inteligentes.
- Las plataformas de nube más populares ofrecen entornos y herramientas integradas, las cuales son muy interesantes y flexibles, pero pueden hacer que los usuarios dependan de cadenas de herramientas restrictivas y de opciones de implementación limitadas.
- El uso de distintas plataformas por parte de los desarrolladores de aplicaciones y los analistas de datos puede dificultar la colaboración y ralentizar el desarrollo.
- La implementación de las aplicaciones inteligentes según sea necesario puede ser un proceso dificultoso, en especial si se utilizan distintas plataformas para el desarrollo y la producción.
Al ser un servicio de nube gestionado, Red Hat® OpenShift® Data Science ofrece a los analistas de datos y los desarrolladores una plataforma de IA/ML eficiente para diseñar e implementar aplicaciones inteligentes. Las empresas pueden probar una variedad de herramientas, colaborar en una plataforma común y agilizar la comercialización, todo desde un mismo lugar. OpenShift Data Science combina el entorno de autoservicio que buscan los analistas de datos y los desarrolladores con la seguridad que exige la TI empresarial.
Los inconvenientes que surgen a lo largo del ciclo de vida se reducen gracias al uso de una base confiable. OpenShift Data Science ofrece una plataforma sólida, un ecosistema amplio de herramientas certificadas y cargas de trabajo conocidas para la implementación de modelos en la etapa de producción. Gracias a estas ventajas, los equipos pueden colaborar con menos contratiempos y comercializar las aplicaciones inteligentes de manera más eficiente, lo cual genera más ganancias para la empresa.
Desarrollo, entrenamiento, pruebas e implementaciones ágiles
OpenShift Data Science se basa en el proyecto comunitario Open Data Hub y en Operate First. Open Data Hub muestra una plataforma de IA/ML en Red Hat OpenShift con iniciativas upstream como Apache Kafka y Kubeflow. Operate First integra el open source a las operaciones, lo cual permite que los desarrolladores y los operadores colaboren para lograr la excelencia operativa, sin depender de un solo proveedor. OpenShift Data Science aporta un subconjunto de herramientas de Open Data Hub en un servicio de nube con soporte completo que se gestiona en Amazon Web Services (AWS) con ofertas opcionales de proveedores de software independientes (ISV).
Pruebe una variedad de herramientas
Con OpenShift Data Science, los analistas de datos pueden probar y descubrir nuevas formas de integrar la información a las empresas. Como se trata de un servicio de nube totalmente gestionado, los analistas de datos pueden desarrollar, entrenar y probar los modelos de aprendizaje automático antes de implementarlos. Los equipos obtienen acceso a las herramientas avanzadas que se ofrecen en una experiencia integrada. Los analistas de datos pueden utilizar herramientas conocidas o acceder a un ecosistema de partners tecnológicos cada vez más grande para disfrutar de una experiencia de IA/ML más profunda, todo sin tener que lidiar con una cadena de herramientas prescriptiva. En lugar de esperar a que la TI proporcione los recursos necesarios mediante una solicitud, obtienen acceso a la infraestructura con un solo clic.
Colabore en una plataforma común
OpenShift Data Science se basa en una arquitectura open source diseñada para las cargas de trabajo de aprendizaje automático y los flujos de trabajo de desarrollo. Acorta la brecha entre los equipos de análisis de datos y DevOps, lo cual disminuye los inconvenientes relacionados con el traspaso de ciertas tareas a la etapa de producción. Los analistas colaboran en tiempo real con Jupyter Notebooks. Los desarrolladores integran los modelos listos para los contenedores a las aplicaciones inteligentes sin problemas. El control ya no es una prioridad para la TI, por lo que no se encarga de buscar cuentas de plataformas de nube no autorizadas.
Agilice la comercialización de las aplicaciones inteligentes
OpenShift Data Science agiliza la integración de los modelos de aprendizaje automático de los primeros pilotos a las aplicaciones inteligentes en una plataforma uniforme y compartida. Los analistas de datos pueden comenzar a trabajar rápidamente con las herramientas que elijan y acceder a una infraestructura de autoservicio. El servicio conecta cada etapa del ciclo de vida del aprendizaje automático con funciones de la IA más profundas a través de su ecosistema de partners de software. Esto le permite tener a su disposición una amplia variedad de herramientas certificadas y especializadas en IA/ML. Puede implementar los modelos en entornos de nube híbrida, lo cual le brinda la flexibilidad necesaria para ejecutar las cargas de trabajo donde sea necesario, sin depender de una nube comercial.
OpenShift Data Science
En la Figura 1 podemos ver la manera en la que el ciclo de vida operativo de los modelos se integra a la oferta inicial de OpenShift Data Science como una plataforma común. Este servicio de nube está disponible en Red Hat OpenShift Dedicated (en AWS) y en Red Hat OpenShift Service on AWS. Proporciona un flujo de trabajo de análisis de datos principal como un servicio gestionado de Red Hat y permite aumentar las funciones y la colaboración a través de un software certificado por los ISV. Los modelos se alojan en el servicio de nube de OpenShift o se exportan para integrarlos a una aplicación inteligente.
Aspectos destacados
- Utilice las herramientas que prefiera sin preocuparse por la infraestructura.
- Disminuya los problemas y colabore en una plataforma común que reúne a los equipos de análisis de datos, desarrollo y operaciones de TI.
- Agilice la distribución de las aplicaciones inteligentes y disminuya el tiempo de comercialización.
- Prepare a los analistas de datos al brindarles una variedad de aplicaciones y servicios de un amplio ecosistema de partners.
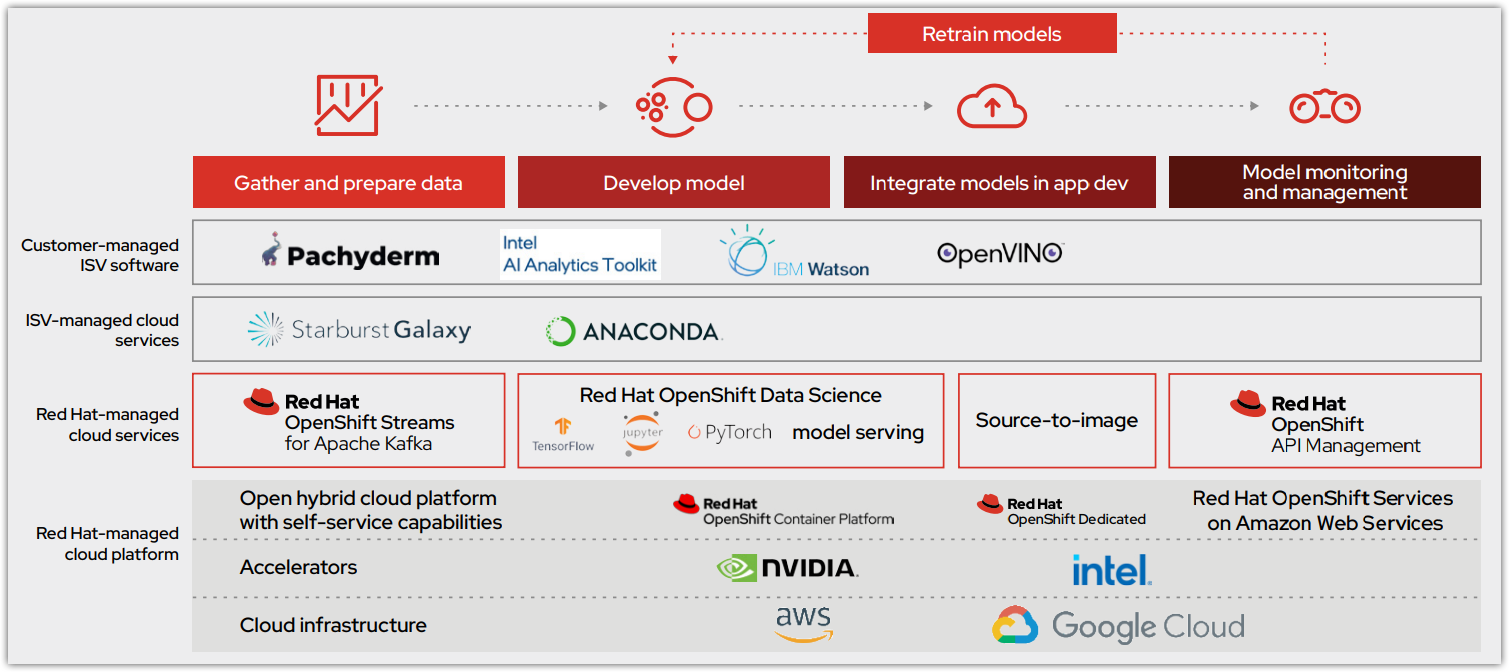
Las funciones y herramientas principales que proporciona OpenShift Data Science tienen una base sólida:
- Jupyter Notebooks: los analistas de datos pueden llevar a cabo un análisis de datos exploratorio en JupyterLab con acceso a las bibliotecas y los marcos principales de IA/ML, incluidos TensorFlow y PyTorch.
- Source-to-Image (S2I): no solo es posible publicar los modelos como extremos a través de la herramienta S2I para su integración a las aplicaciones inteligentes, sino también volver a diseñarlos e implementarlos según los cambios en el notebook fuente.
- Inferencia optimizada: los modelos de aprendizaje profundo se pueden convertir en motores de inferencia optimizada para agilizar los proyectos experimentales.
Red Hat ofrece imágenes de Jupyter Notebook para TensorFlow y PyTorch como parte del servicio, lo cual simplifica la adopción de estas tecnologías potentes para los equipos, ya que no tienen que empezar de cero. Para obtener mayor uniformidad y flexibilidad, el generador de Jupyter proporciona las imágenes personalizadas de una empresa a los equipos de analistas de datos, con las bibliotecas, las herramientas y los lenguajes preferidos. El servicio también incluye el complemento Git para JupyterLab, con lo que se requiere menos tiempo para integrarse a Git directamente desde la interfaz de JupyterLab. Pandas, scikit-learn y NumPy son otros paquetes de análisis comunes que se proporcionan como parte del servicio, los cuales simplifican las operaciones y facilitan la puesta en marcha de su proyecto con las herramientas adecuadas.
Otra de las características propias de este servicio de nube gestionado es que Red Hat brinda el soporte del equipo de ingeniería de confiabilidad del sitio (SRE) para la plataforma subyacente de aplicaciones OpenShift y el servicio OpenShift Data Science. Esto le permite concentrarse en el análisis de su empresa, y no en la plataforma subyacente. Red Hat garantiza una alta disponibilidad del servicio Red Hat OpenShift Data Science, que incluye el entorno subyacente de servicios de nube gestionados Red Hat OpenShift. Todas las mejoras, actualizaciones y compatibilidades se gestionan como parte del servicio, lo cual evita tener que realizar un seguimiento de las matrices de compatibilidad potencialmente complejas entre las herramientas de análisis.
Herramientas para el ciclo de vida completo del modelo
OpenShift Data Science proporciona los servicios y los sistemas de software que permiten que las empresas implementen sus modelos con éxito y los trasladen a la etapa de producción (Figura 2). Este proceso se integra a Red Hat OpenShift API Management, además de OpenShift Data Science.

Para que la adopción sea más sencilla, el panel de Red Hat OpenShift Data Science proporciona un espacio central para detectar todas las aplicaciones y la documentación, y acceder a ellas. Los tutoriales Smart Start ofrecen orientación en torno a las prácticas recomendadas para los elementos comunes y los sistemas de software de partners integrados. Además, están disponibles directamente desde el panel, lo cual permite que los analistas de datos adquieran la información necesaria y pongan en marcha sus proyectos con mayor rapidez. En estas secciones se describen las principales herramientas de análisis que se incluyen con Red Hat OpenShift Data Science.
Starburst
Starburst agiliza el análisis al permitir que los equipos saquen el máximo provecho de los datos de manera sencilla y rápida para mejorar el funcionamiento de la empresa. Se distribuye como un producto autogestionado o un servicio totalmente gestionado y permite que todos puedan acceder a los datos, de manera que los consumidores posean información más completa. Starburst se basa en Trino (antes conocido como PrestoSQL), el motor principal de SQL de procesamiento paralelo masivo (MPP), que cuenta con tecnología de open source. Está herramienta, cuyo diseño y operación está a cargo de los especialistas en Trino y los creadores de Presto, permite analizar los distintos conjuntos de datos donde sea que se encuentren, sin tener que trasladarlos.
Se integra a los servicios flexibles de almacenamiento en la nube y cloud computing de Red Hat OpenShift para que pueda consultar todos sus datos empresariales con mayor estabilidad, seguridad, eficiencia y rentabilidad. Estas son algunas de las ventajas que ofrece:
- Automatización. Los operadores de Starburst y Red Hat OpenShift facilitan la configuración, el ajuste y la gestión automáticos de los clústeres.
- Alta disponibilidad y facilidad para reducir los recursos. El equilibrador de carga de Red Hat OpenShift mantiene a ciertos servicios, como el coordinador de Trino, en permanente funcionamiento.
- Capacidad de ajuste flexible. Red Hat OpenShift puede ajustar automáticamente el clúster de trabajo de Trino según la carga de la consulta.

Anaconda Commercial Edition
Anaconda Commercial Edition proporciona acceso a un amplio conjunto de paquetes de análisis de datos para su uso en los proyectos de Jupyter, con imágenes prediseñadas a las que puede acceder directamente desde el panel de Red Hat OpenShift Data Science. Además, otorga a las empresas acceso a la experiencia de distribución y gestión de paquetes open source más popular del mundo, la cual se encuentra optimizada para su uso comercial e incluye:
- Innovación open source, con más de 7500 paquetes seleccionados de análisis de datos y aprendizaje automático en el repositorio de primera categoría de Anaconda.
- Funciones de confianza en el contenido, como la verificación de firmas de Conda, las cuales evitan que los procesos de análisis de datos y aprendizaje automático se vean afectados por sistemas de software poco confiables y puntos vulnerables.
- Tranquilidad y confianza, gracias a los acuerdos de nivel de servicio (SLA) de tiempo de actividad y el soporte para los flujos de trabajo de la etapa de producción.
- Cumplimiento normativo completo para el uso comercial según las condiciones de servicio de Anaconda.
IBM Watson Studio
IBM Watson Studio1 permite diseñar, ejecutar y gestionar modelos de inteligencia artificial según sea necesario con Watson Machine Learning y Watson OpenScale. La plataforma combina marcos open source, como PyTorch, TensorFlow y scikit-learn, con IBM y su ecosistema de herramientas para el análisis de datos visual y basado en el código. La plataforma funciona con Jupyter Notebooks, JupyterLab, las interfaces de línea de comandos (CLI) y los lenguajes de Python.
IBM Watson permite aplicar la inteligencia artificial y fomenta la confianza desde los conceptos básicos hasta la práctica. Los procesos transparentes aportan información para las decisiones basadas en la IA. IBM Watson garantiza la privacidad, el cumplimiento y la seguridad de los datos en los sectores estrictamente regulados, y respalda un ecosistema diverso y abierto que promueve el uso responsable de la IA. IBM Watson Studio ofrece:
- AutoAI y AutoML (procesos automatizados de IA/ML) para diseñar, generar y clasificar canales de modelos; preparar los datos, y seleccionar los tipos de modelos, todo de manera automática.
- Herramienta avanzada de perfeccionamiento de los datos para limpiarlos y estructurarlos mediante un editor de flujos gráficos.
- Herramientas visuales integradas a través de IBM SPSS Modeler para preparar los datos con rapidez y desarrollar los modelos visualmente.
- Desarrollo y entrenamiento de los modelos para diseñar pruebas experimentales rápidamente con procesos optimizados.
- Herramienta integrada de optimización de la toma de decisiones para combinar los modelos predictivo y prescriptivo.
- Gestión de los modelos y control de la calidad, la equidad y los indicadores de desajuste.
- Exportación de los modelos como Python Jupyter Notebook.

Pachyderm
Las empresas necesitan soluciones para la gestión de los datos que ayuden a simplificar todos los procesos, desde las pruebas que se llevan a cabo en las computadoras portátiles hasta las implementaciones empresariales importantes. Pachyderm permite que los equipos de análisis de datos diseñen y ajusten los canales de aprendizaje automático basados en los datos y organizados en contenedores con el linaje de datos garantizado que proporciona el control de versiones. Esta herramienta, diseñada para solucionar los problemas reales del análisis de datos, proporciona la base que permite que los equipos automaticen y ajusten su ciclo de vida de aprendizaje automático y, al mismo tiempo, garanticen la capacidad de reproducción. Además de los casos prácticos que abarcan desde los datos sin estructurar hasta los almacenes; el procesamiento del lenguaje natural; la extracción, transformación y carga de videos e imágenes; los servicios financieros y las ciencias biológicas, Pachyderm ofrece:
- Automatización del control de versiones de datos que otorga a los equipos una opción de alto rendimiento para seguir los cambios.
- Canales organizados en contenedores y basados en los datos que agilizan el procesamiento y, al mismo tiempo, disminuyen los costos informáticos.
- Un linaje de datos inmutable que proporciona un registro fijo para todas las actividades y los recursos del ciclo de vida del aprendizaje automático.
- La consola de Pachyderm, que ofrece una visualización intuitiva de los grafos acíclicos dirigidos (DAG) y asiste en las tareas de depuración y reproducción.
- Compatibilidad entre Jupyter Notebook y la extensión JupyterLab Mount de Pachyderm para acceder a una interfaz interactiva con las diferentes versiones de los datos de Pachyderm.
- Administración empresarial con herramientas sólidas para implementar y gestionar Pachyderm según sea necesario en los distintos equipos dentro de la empresa.

Análisis de datos agilizado de NVIDIA
El procesamiento de datos flexible, el análisis de datos, el entrenamiento del aprendizaje automático y las inferencias son ejemplos de tareas informáticas que utilizan muchos recursos. El software de NVIDIA permite agilizar todos los aspectos del análisis de datos integral, ya que aprovecha las funciones de procesamiento paralelo de las GPU. Ni el ajuste de los recursos de las GPU locales ni la configuración de las implementaciones de Kubernetes para su uso deberían desviar la atención de los analistas, quienes preferirían trabajar para obtener valor de sus datos.
Actualmente, existen distintas empresas que utilizan las soluciones de NVIDIA para el aprendizaje automático y un host de otros servicios. OpenShift Data Science disminuye la complejidad de poner en marcha un hardware habilitado para GPU que agilice las pruebas de análisis de datos que consumen muchos recursos. Con esta plataforma, las empresas pueden aplicar las instancias de Amazon Elastic Computing (EC2) que utilizan las GPU de NVIDIA según sea necesario, y así ampliar o reducir los recursos informáticos.

Kit de herramientas de Intel OpenVINO
La distribución de Intel del kit de herramientas OpenVINO agiliza el desarrollo y la implementación de las aplicaciones de inferencia de aprendizaje profundo de alto rendimiento en las plataformas de Intel. El kit permite diseñar, optimizar, ajustar y ejecutar inferencias completas de IA utilizando el optimizador de modelos que se incluye junto con las herramientas de tiempos de ejecución y de desarrollo.
- Diseño. Los desarrolladores pueden utilizar Open Model Zoo para buscar modelos open source previamente entrenados y optimizados y listos para realizar inferencias; o bien, pueden utilizar sus propios modelos de aprendizaje profundo.
- Optimización. La herramienta Model Optimizer puede convertir un modelo en una representación intermedia (IR), lo cual da como resultado un par de archivos que describen la topología de la red y contienen los pesos y sesgos del modelo.
- Implementación. El motor de inferencia genera resultados de varios procesadores, aceleradores y entornos con un enfoque eficiente que se basa en escribir el código una sola vez e implementarlo en todas partes.

Kit de herramientas de análisis de IA de Intel®
El kit de herramientas Intel® AI Analytics ofrece herramientas y marcos conocidos de Python a los analistas de datos, los desarrolladores de inteligencia artificial y los investigadores para agilizar los procesos integrales de análisis en las arquitecturas de Intel. Los elementos utilizan bibliotecas de oneAPI para las optimizaciones informáticas de menor importancia. Este kit potencia el rendimiento del procesamiento previo a través del aprendizaje automático y ofrece interoperabilidad para un desarrollo de modelos eficiente.
Con el kit de herramientas Intel AI Analytics, puede:
- Ofrecer el entrenamiento de aprendizaje profundo de alto rendimiento en las unidades XPU de Intel e integrar las inferencias rápidas a su flujo de trabajo de desarrollo de inteligencia artificial con los marcos de DL optimizados para Intel para TensorFlow y PyTorch, modelos entrenados anteriormente y herramientas de baja precisión.
- Acelerar de manera instantánea el procesamiento previo de los datos y los flujos de trabajo de aprendizaje automático con los paquetes de Python que consumen muchos recursos informáticos, Modin, scikit-learn y XGBoost, los cuales están optimizados para Intel.
- Obtener acceso directo al análisis y las optimizaciones de la inteligencia artificial de Intel para garantizar que su sistema de software funcione en conjunto y sin interrupciones.
Conclusión
Gracias a OpenShift Data Science, las empresas pueden probar, colaborar y, finalmente, agilizar su proceso de adopción de aplicaciones inteligentes. El servicio complementario basado en la nube y gestionado por Red Hat simplifica y agiliza la experimentación de los analistas de datos, una plataforma de IA/ML moderna organizada en contenedores y la comodidad y capacidad de ajuste de AWS. Las herramientas de autoservicio a las que pueden acceder los desarrolladores y los analistas de datos agilizan la generación de innovaciones en una plataforma de aplicaciones que la TI empresarial ya utiliza y en la que confía plenamente. A diferencia de los enfoques de la competencia, los analistas pueden elegir las herramientas con las que quieren trabajar, lo cual aporta nueva información sin implementar limitaciones arbitrarias.
IBM Watson Studio y Watson Machine Learning son parte de la oferta Cloud Pak for Data de IBM.
